Crushing Fantasy Sports Leaderboard
Crushing Fantasy Sports Leaderboard¶
Leverage historical data and Integer Linear Programming for selecting an optimal fantasy team.¶
Sports have played a pivotal role in our society for ages. It has been an active medium for entertainment and a means for uniting people.
Sports have given us legends who are followed, loved, and worshipped across the globe.
Over the last few years, the emergence of fantasy sports platforms has allowed fans to connect with sports on a deeper level.
According to a recent report published by Businesswire, North American Fantasy Sports Markets are expected to grow at a staggering CAGR of 10.7% over the next five years.
The story is no different in India, Asia. The fantasy sports platform, Dream11, has grown its user base by a jaw-dropping 6000% from a few lakh in 2015 users to over eight crore active users in 2020.
Selecting a fantasy team that is capable of earning the maximum points is not trivial. Often, emotions take over and your team ends up at the bottom of the points table in the fantasy league.
In this blog post, we shall explore a data-driven approach for selecting the fantasy team objectively given historical data.
Data Description -¶
- For the sake of this blog, let’s focus on the game of cricket. Technically, once we have chalked out the details it is trivial to extend the logic for other sports.
- I have managed to dump the historical fantasy points data for two of the biggest teams in the Indian Premier League (IPL), Chennai Super Kings and Mumbai Indians, in a CSV file.
The input file for auto-selecting players has the following fields -
- Cost - Most of the fantasy websites (including Dream11) allocate a total budget which cannot be exceeded.
- last_5_matches_points - This field is a list of points accrued by a player in his last 5 matches.
- player_category - This field highlights the category of the player. In the case of cricket, the possible categories are wicket-keeper, batsman, all-rounder, bowler. For a sport like football, the possible categories are - Goalkeeper, Defender, Midfielder, Striker. This field is important because every fantasy website restricts the number of players one can select from each of these categories.
- player_name - This field highlights the player name on a fantasy sports website.
- team_name - This column in the data frame highlights the team name of the player.
Let's get right to it by loading and inspecting the player data for an upcoming match between Chennai Superkings vs Mumbai Indians.¶
##import python libraries
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "none"
from IPython.display import display
from IPython.display import HTML
import os
import sys
import re
import pandas as pd
import numpy as np
from ast import literal_eval
import pulp
from typing import List, Dict
from sklearn.preprocessing import LabelBinarizer
from IPython.core.display import display,HTML
display(HTML('<style>.prompt{width: 0px; min-width: 0px; visibility: collapse}</style>'))
display(HTML("<style>.container { width:100% !important; }</style>"))
raw_player_data = pd.read_csv('https://raw.githubusercontent.com/jadhavpritish/Dream11_Predictor/master/data/dream11_performance_data.csv', converters={"last_5_matches_points": literal_eval})
display(raw_player_data[["team_name", "player_name", "player_category", "last_5_matches_points", "cost"]].style.set_properties(**{'background-color':'#f7ebcf'}))
What are we trying to achieve?¶
- Given the player attributes and their historical fantasy sports (at least for the last five matches), we would want to select a team of 11 players such that the probability of us winning the fantasy league is maximized.
- Certain constraints must be satisfied while selecting the fantasy team that makes the whole process engaging and exciting.
The summary of rules for selecting a cricket team on Dream11 is as follows -¶
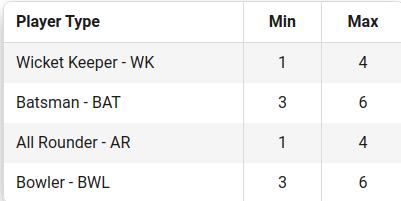
Every cricket team you build on Dream11 has to have an exact of 11 players. We can select a maximum of 7 players can be from the same team.
The captain will give you 2x points scored by them in the actual match.
- The vice-captain will give you 1.5x points scored by them in the actual match.
Algorithm for selecting an Optimal Fantasy Team -¶
- We shall frame the selection problem using Integer Linear Programming (ILP) with constraints.
- For the sake of convenience, we shall skip the selection of caption and vice-captain in this implementation.
- The objective function for ILP (Integer Linear Programming) will be to maximize the expected points while honoring the constraints mentioned above.
- Once we define the ILP problem in python, we shall use the PuLP library in python for solving the problem.
So without further adieu, let’s get down to coding.¶
Data Preprocessing -¶
1. Handling Categorical Variables¶
- The team_name and player_category columns in our data are categorical features.
- For specifying the constraints on our ILP objective function, we need to convert these features into one-hot encoded vectors. A single line of python code helps us achieve this.
def get_dummies(data, col_names = ["player_category", "team_name"]):
dummies_data = pd.get_dummies(raw_player_data, columns=col_names)
return dummies_data
processed_player_data = pd.get_dummies(raw_player_data, columns=["player_category", "team_name"])
display(processed_player_data.drop(['cost', 'last_5_matches_points'], axis = 1).head().style.set_properties(**{'background-color':'#f7ebcf'}))
2. Computing the Estimated Points per player.¶
- The objective function is designed to maximize the summation of estimated points for the fantasy team.
- We have access to every player’s historical points, but we still need to compress them into point estimates that reflect each player’s worth.
- A simple way to achieve this would be to compute the mean fantasy points accrued by each player over the last 5 matches.
However, using an averaging aggregation can be misleading because we would want to capture the recent form of a player more accurately. To achieve this, we shall leverage the weighted averaging technique.
To demonstrate this further, let us consider an example, say, the fantasy points scored by player-1 and player-2 in the last 5 matches are as follows -
player-1 - [10, 20 , 30 , 40 , 50]
player-2 - [50, 40 , 30, 20 , 10]
- Computing simple averages results in an aggregated score of 30 for both players.
- However, the data suggests that player-1 is growing in confidence and has an upward trend in his performance. On the other hand, player-2 has a downward trend in his performance.
- By taking a simple average, we are losing an important insight.
- If we compute the averages using time decayed weights such that the most recent performance has a higher weight as compared to older performances resulting in an aggregated score of 33.93 and 26.06 for player-1 and player-2, respectively.
- As can be seen from the above numbers that even though both the players have amassed the same number of points, the trend in performances is now being captured with player-2 getting a higher average as compared to player-1.
- Such subtle differences will help us build a robust model.
So, let’s compute the time decayed weighted averages for the eligible players in the dataset.¶
def compute_weighted_points(points_vector, alpha = 0.20):
# compute weights such that recent values are assigned a higher weight as compared to the older values.
weights = np.exp(list(reversed(np.array(range(1, len(points_vector)+1))*alpha * -1)))
exponential_weighted_average = np.average(np.array(points_vector), weights = weights)
return exponential_weighted_average
processed_player_data['weighted_player_points'] = processed_player_data['last_5_matches_points'].apply(compute_weighted_points)
processed_player_data.reset_index(inplace = True)
display(processed_player_data[['player_name', 'last_5_matches_points', 'weighted_player_points']].style.set_properties(**{'background-color':'#f7ebcf'}))
Now, let's define the constraints for selecting players as defined by Dream11. These constraints are to be honored by the algorithm while trying to maximize points.
For more information, check out dream11 FAQs.
# Initialize the optimization Problem
prob = pulp.LpProblem('Dreamteam', pulp.LpMaximize)
# selection decision variables can be 0 or 1. The number of `selection_decision_varibales` should be equal to
# the number of players under consideration
selection_decision_variables = []
for row in processed_player_data.itertuples(index=True):
variable_name = 'x_{}'.format(str(row.Index))
variable = pulp.LpVariable(variable_name, lowBound = 0, upBound = 1, cat = 'Integer' )
selection_decision_variables.append({"pulp_variable":variable, "player_name": row.player_name})
selection_decision_variables_df = pd.DataFrame(selection_decision_variables)
merged_processed_player_df = pd.merge(processed_player_data, selection_decision_variables_df,
on = "player_name")
merged_processed_player_df["pulp_variable_name"] = merged_processed_player_df["pulp_variable"].apply(lambda x: x.name)
display(selection_decision_variables_df)
# Create the objective Function to be maximized
total_points = pulp.lpSum(merged_processed_player_df["weighted_player_points"] * selection_decision_variables_df["pulp_variable"])
prob += total_points
display(prob)
# 1 <= n_keeper <= 4
total_keepers = pulp.lpSum(merged_processed_player_df["player_category_wicket_keeper"] * selection_decision_variables_df["pulp_variable"])
prob += (total_keepers >= 1)
prob += (total_keepers <= 4)
# 3 <= n_batsmen <= 6
total_batsmen = pulp.lpSum(merged_processed_player_df["player_category_batsman"] * selection_decision_variables_df["pulp_variable"])
prob += (total_batsmen >= 3)
prob += (total_batsmen <= 6)
# 1 <= n_allrounders <= 4
total_allrounders = pulp.lpSum(merged_processed_player_df["player_category_all_rounder"] * selection_decision_variables_df["pulp_variable"])
prob += (total_allrounders >= 1)
prob += (total_allrounders <= 4)
# 3 <= n_bowlers <= 6
total_bowlers = pulp.lpSum(merged_processed_player_df["player_category_bowler"] * selection_decision_variables_df["pulp_variable"])
prob += (total_bowlers >= 3)
prob += (total_bowlers <= 6)
# maximum of 11 players
total_players = pulp.lpSum(selection_decision_variables_df["pulp_variable"])
prob += (total_players == 11)
# maximum fantasy budget of 100
total_cost = pulp.lpSum(merged_processed_player_df["cost"] * selection_decision_variables_df["pulp_variable"])
prob += (total_cost <= 100)
# we cannot pick more than 7 players from the same team
total_team1 = pulp.lpSum(merged_processed_player_df["team_name_CSK"] * selection_decision_variables_df["pulp_variable"])
prob += (total_team1 <= 7)
total_team2 = pulp.lpSum(merged_processed_player_df["team_name_MI"] * selection_decision_variables_df["pulp_variable"])
prob += (total_team2 <= 7)
display(prob)
prob.writeLP('Dreamteam.lp')
assert len(pulp.listSolvers(onlyAvailable=True)) > 0, "solvers not installed correctly - check - https://www.coin-or.org/PuLP/main/installing_pulp_at_home.html"
prob.solve()
# prep solution
solutions_df = pd.DataFrame(
[
{
'pulp_variable_name': v.name,
'value': v.varValue
}
for v in prob.variables()
]
)
result = pd.merge(merged_processed_player_df, solutions_df, on = 'pulp_variable_name')
result = result[result['value'] == 1].sort_values(by = 'weighted_player_points', ascending = False)
selected_cols_final = ['player_name', 'team_name_CSK', 'team_name_MI', 'weighted_player_points']
final_set_of_players_to_be_selected = result[selected_cols_final]
display(final_set_of_players_to_be_selected.style.set_properties(**{'background-color':'#f7ebcf'}))
print("We can accrue an estimated points of %f"%(final_set_of_players_to_be_selected['weighted_player_points'].sum()))
There you GO !! We have our Dream Team !!¶
All that needs to be done is to select the team in the app and start earning money !!
Before we wrap up this tutorial, I would like to highlight the features as well as the enhancement opportunities for the existing algorithm -
a. The existing algorithm is completely automated and spits out the Dream team that maximizes the probability of scoring the highest points.
b. In addition to that, it also conveys the estimated points that can be accrued through the selected team. The value would help us check the accuracy of the system.
c. The algorithm is sensitive to player performance trends and it adjusts accordingly.
Enhancements -
a. The input data needs to be stored in a database. Currently, I am relying on manual efforts to fetch the required data.
b. The algorithm is not sensitive to injury news and other team updates. This is a significant miss and we will have to rely on scrapping and detecting such information through NLP on sports websites. It is an open-ended question.